
Этот текст взят из большой статьи, написанной не для блога. На мой взгляд, получилось интересно, поэтому выставляю в блоге. Выставляю без редактирования, так что извиняюсь за возможные нестыковки.
Основные идеи и подходы, заложенные в среду разработки «Вир» в начале, сохраняются неизменными, это:
- Явная схема программы;
- Сборка программ из бинарных компонент.
- Репозиторий стандартных компонент;
- Независимость программы от ОС.
Разберем подробнее эти идеи и их реализацию.
Явная схема программы
В большинстве случаев, современные программы в бинарной форме слабо структурированы. На стадии проектирования могут быть использованы различные методы представления архитектуры. Далее, вручную или с помощью инструментов, строится исходный текст программы, в котором архитектура программы размазана. И дальше, компилятор, особенно сильно оптимизирующий, удаляет оставшиеся следы архитектуры.
Как правило, из бинарной программы восстановить архитектуру программы невозможно. Более того, так как далее разработка продолжается, как правило, на уровне исходного кода, то соответствие между архитектурой программы и исходным кодом теряется частично или полностью.
Единственным средством явного структурирования программы являются DLL (SO), но использование DLL накладывает существенные ограничения на способы разработки и развития программ. Вплоть до того, что, например, в языке Go постулируется статическая сборка программ, чтобы не сталкиваться с проблемами динамической сборки.
Альтернатива DLL существовала в реализациях модульных языков программирования, например, в системе Оберон [7] или в OS Excelsior iV [8], написанной на языке Модула-2. В обоих случаях, использовалась раздельная компиляция модулей и динамическая загрузка. При запуске программы, которая была представлена головным модулем программы, динамически подгружались используемые (импортируемые) модули, кроме тех, которые уже были загружены.
Схема работающей программы при этом сохранялась в виде таблиц импорта для каждого модуля. Схему можно было извлечь из бинарных образов модулей и симфайлов, в которых хранилась информация об экспорте/импорте каждого модуля.
К сожалению, вместо развития модульных языков, которое могло привести к устранению их недостатков, IT пошло по пути использования слабоструктурированных языков, ярким примеров которых является С++.
Критика слабоструктурированных языков выходит за рамки данной статьи. Замечу лишь то, что использование ООП далеко не всегда увеличивает структурность, а часто приводит к более запутанному и трудно поддерживаемому коду. ООП, исходя из общих соображений на философском уровне, это, безусловно, правильный подход. Но вот современные реализации подкачали, впрочем, некоторый прогресс существует, например, в языке Go.
Более существенное продвижение, на мой взгляд, произойдет, когда мы осознаем, что в большинстве ООП языков реализовано вовсе не object-oriented programming, а class-oriented programming (CLOP) и перейдем к OOP, опираясь на объекты, а не классы. В каком-то смысле аббревиатура CLOP (намекающая на bugs) является шуткой, но в которой, как и в любой шутке, есть доля шутки.
Вернемся к схеме программ, характерной для модульных языков. Для них схема – это дерево, корнем которого является головной модуль программы, а переходы к узлам – это использование модуля (импорт).
Пример модульной схемы, модуль А – головной модуль программы:
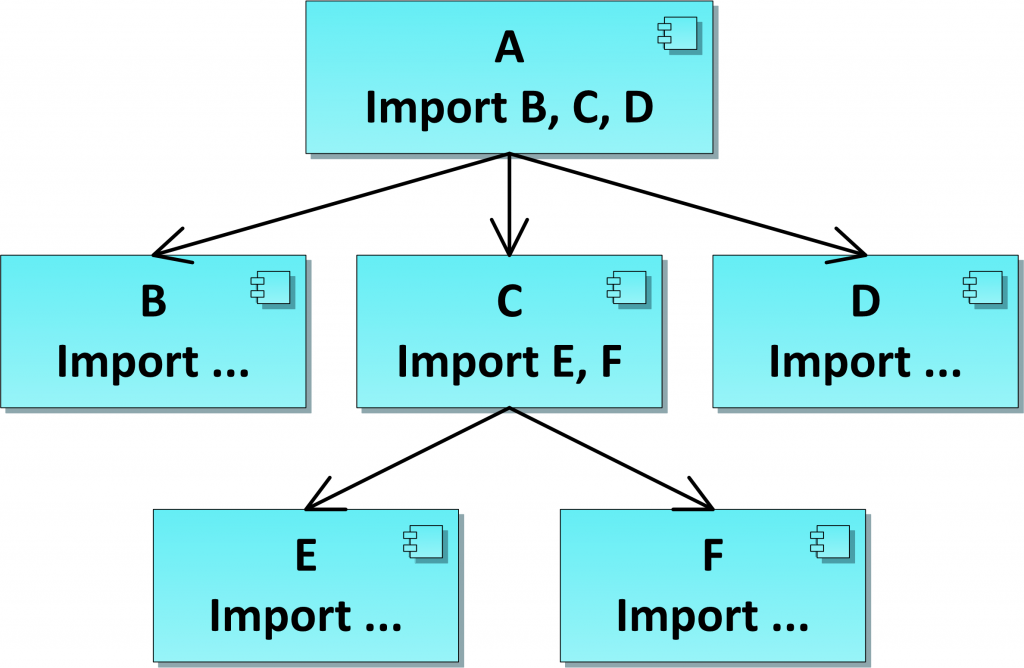
Перечислим недостатки модульной схемы:
- Устройство схемы или направление роста дерева. Корень дерева в модульной схеме – это модуль верхнего уровня, то есть модуль, обращенный к пользователю (для нас не важно, пользователь – это человек или программная часть). А это приводит к тому, что при любом изменении функциональности, корень дерева меняется. И это еще полбеды, гораздо хуже, что головной модуль становится узким местом при изменениях программы. Гораздо естественнее для «живой» модифицируемой программы схема, в которой корень находится внизу, и из него разворачивается функциональность.
- Статичность схемы. Во-первых, изменение схемы делается только добавлением импорта в модуль и компиляцией. Динамическое изменение/построение новой схемы невозможно. Во-вторых, для использования компоненты необходимо при разработке иметь доступ к описанию её интерфейса. А если интерфейс изменился, то необходима перекомпиляция. Казалось бы, что этот недостаток преодолевается использованием средств ООП – описанием базового класса и наследованием (и еще нужна фабрика объектов или подобные механизмы). Да, но только частично. Хотя бы базовый класс должен быть описан во время разработки использующей компоненты. А при использовании базового класса мы постоянно сталкиваемся с типичной проблемой CLOP – изменение в базовом классе приводит к перекомпиляции всех наследников. Еще более важно, что как только мы добавили ООП, мы потеряли простоту и ясность модульной схемы.
- Следующий недостаток модульной схемы, о котором подробнее будем говорить позже, это то, что все узлы в модульной схеме одного и того же уровня. Понятно, что модули могут быть разного размера, но это не создает вложенность. В схеме программы должна присутствовать вложенность иерархий (например, дерево деревьев), иначе схема будет пригодна только для простых программ.
Реализуя явную схему программы в среде «Вир» нам удалось избежать перечисленных выше недостатков модульных схем. Рассмотрим подробнее.
Устройство схемы в среде «Вир»
Корень программы – это самая низкоуровневая компонента, содержащая инструменты программы, необходимые для её запуска. Далее разворачивается дерево компонент высокого уровня. Компоненты высокого уровня мы называем «рабочими столами». При этом каждый рабочий стол – это дерево компонент. Таким образом, дерево обращено к пользователю кроной. Ближе к корню располагаются более «сервисные» компоненты. Ближе к кроне компоненты, более ориентированные на пользователя, не важно, кто/что является пользователем — человек либо программа.
Принципиально важно то, что схема отделена от компонент. Схема первична, компоненты вторичны. Если у нас есть схема программы, то любой компонент можно заменить на другой без изменения/компиляции компонента. И программа продолжит работать, если эти компоненты, старая и новая, «совместимы» (об этом позже).
Рассмотрим пример схемы программы. На верхнем уровне схема состоит из рабочих столов (РС). Каждый рабочий стол определяется под-деревом.
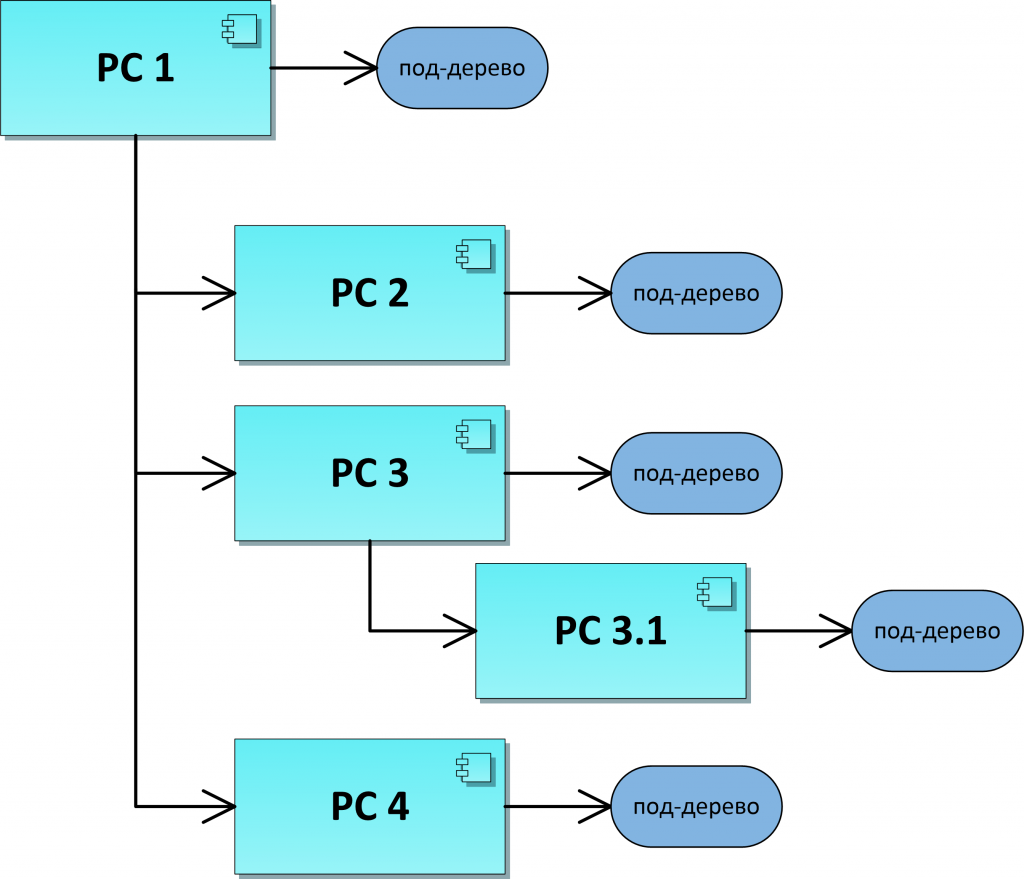
Схема в «Вире» позволяет добавлять функциональность не только статически, но и «на лету», например, за счет скачивания дополнительных компонент из облака. Например, таким способом реализован механизм подключения «дополнений» (add-ons). Причем, этот механизм работает не для конкретной программы, а может быть применен в любой из создаваемых программ. Кроме механизма подключения «дополнений» таким способом реализовано множество подобных «сервисов».
Взаимодействие компонент
Ранее был упомянут один из недостатков модульной схемы, статичность схемы и статичность подключения компонент через импорт.
Каким образом реализовано взаимодействие компонент в «Вире»? Способ связи компонент, то есть способ, каким компонента подключаются к тем компонентам, которые нужны для её работы, пожалуй, есть самая необычная часть нашей технологии.
Мы не используем статические механизмы подключения, типа import/include. Связь строится на взаимном расположении компонент в схеме (в иерархии). Например, если компонента А всегда использует компоненты B и С, то скорее всего компоненты B и C будут находится непосредственно над ней в дереве — ближе к корню, т.к. дерево схемы мы рассматриваем растущим вниз.
Но если компонента B используется не только компонентой А, а другими компонентами, например, компонентой D, то компонента В будет сдвинута вверх (к корню дерева), так чтобы быть выше компонент A и D.
Как правило, для того, чтобы компонента могла использовать другую, используется относительный адрес, который записывается в нотации привычной для адресов файлов, например, «../В». В некоторых случаях используется абсолютный или косвенный адрес, но в этой статье мы не будем их рассматривать.
При запуске или при первой необходимости компонента обращается по адресу и получает доступ к используемой компоненте. Первое обращение является динамическим, далее компонента может запомнить адрес (аналогично получению адреса функции из DLL или SO) и далее обращаться напрямую или каждый раз выполнять динамическое обращение. Выбор между способами – это ответственность разработчика компоненты. Для увеличения гибкости, взаимодействие компонент может быть задано на простом скриптовом языке.
Очевидным преимуществом такого способа связи является возможность разработки независимых и заменяемых компонент. Возможный недостаток – это потеря производительности на критических задачах. Но наш подход дает возможности оптимизации, которые были ранее не применимы. Разговор об этом выходит за рамки статьи.
Литература
[7] Wirth and J. Gutknecht. Project Oberon. Addison-Wesley, 1992. 488 p
[8] Кузнецов Д.Н., Недоря А.Е., Тарасов Е.В., Филиппов В.Э. КРОНОС: семейство процессоров для языков высокого уровня. Микропроцессорные средства и системы, 1989.