
Направление движения для меня определено — Интенсивное программирование и так же определена промежуточная точка — семейство языков «Языки выходного дня».
Разработка такого уровня экспериментальности может быть только итеративной — сделали шаг, проверили, вернулись, переделали. Поэтому неверно пытаться сначала полностью разработать ЯВД, а потом идти дальше. Надо как можно быстрее дойти до шага «проверить».
Что для этого нужно? Хотя бы один язык, пусть очень черновой и минимальная экосистема: компилятор, система выполнения, библиотеки.
Тогда вопрос «как идти» можно упростить до «какую минимальную экосистему построить в первую очередь». Требование минимальности исходит из малого количества ресурсов. Я рассчитываю на одну голову и одну пару рук, как это было при разработке системы «Вир». Если еще кто-то подключится, хорошо, если нет: «делай что должен, и будь что будет».
Итак экосистема: язык + компилятор + среда исполнения + минимальный набор библиотек.
Начну с языка. Как я уже писал, семейство предположительно состоит из
- языка уровня 1: динамически типизированный язык (желательно с возможностями gradual typing);
- языка уровня 2: статически типизированный язык с динамическими возможностями и сборкой мусора;
- язык уровня 3: статически типизированный язык с ARC;
- язык уровня 4: статически типизированный язык с ручным управлением памятью.
Эта классификация уже показала свою применимость. Кратко мы говорим, например, L2 (язык уровня 2), и это сразу дает понимание.
Другой взгляд на те же уровни через область применения:
- L1: приложения
- L2: приложения и высокоуровневые библиотеки;
- L3: приложения, критические по производительности или безопасности, и библиотеки;
- L4: ОС, драйверы, низкоуровневые библиотеки.
Понятно, что классификация условная, особенно для языков-монстров типа С++. Кроме того, 4-х уровней явно недостаточно, поэтому надо использовать опыт нумерации строк в Бейсике  и добавить пару нолей, то есть добавить подуровни.
и добавить пару нолей, то есть добавить подуровни.
Если попытаться разбросать существующие языки (не сильно задумавшись и очень примерно):
- Typescript — L100
- Go — L220
- Swift — L300
- Rust — L400
- C++ — L420
- C — L440
- LLVM IR — L470
С какого языка начать? Мой опыт говорит о том, что для проверки языка принципиально важно написать на языке компилятор самого языка (bootstrapping).
Значит, язык должен быть
- маленький и простой с точки зрения компиляции;
- достаточный для того, чтобы на нем написать компилятор (в том числе в последствии и для других языков семейства);
- достаточный для экспериментов с компонентами — впрочем, это не сразу.
На мой взгляд, надо начинать с языка L3. Отсутствие GC упрощает экосистему (хотя потребует weak pointers или чего-то аналогичного).
И тогда последовательность шагов примерно такая.
Этап 1:
- минимальная грамматика языка
- парсер
- минимальный семантический анализ
- кодо-генератор. Думаю, что строить надо код на С, что достаточно просто и еще упрощает взаимодействие с C библиотеками.
- система выполнения на С/С++
- минимальный набор библиотек (в начале обертки для C libraries)
Этап 2:
- bootstrap
- система тестирования
- улучшения
Дальше развитие языка, добавление других языков семейства, эксперименты и тому подобное.
И последний вопрос — на каком языке писать первый компилятор?
Я предпочитаю Go, основные соображение — простой и знакомый язык, кросс-платформенность, бесплатные средства разработки. Впрочем, это почти не важно, так как он нужен только на первом этапе.
Далее: Тривиль
Постоянная ссылка
Выглядит так, что под итерациями Вы понимаете нечто вроде такого?
ПОВТОР
1. Формулируем/корректируем языки
2. Пишем/меняем инструментарий
3. Используем языки
4. Оцениваем
ПОКА не удовлетворит оценка
Если да, то на первом этапе 2-й пункт выглядит слишком замедляющим, ведь, предположительно, какие-то нестыковки можно увидеть до воплощения. Или понимание языков уже, в целом, сформировано и остались корректировки, не требующие значительных переделок в инструментарии?
Постоянная ссылка
Да, итерации примерно такие.
Языки уровня L2 проработаны очень подробно. Проработано даже два разных языка, которые сильно отличались набором дополнительных требований.
Естественно, что ЯВД будет делаться на опыте, но даже L2 в ЯВД будет существенно отличаться, хотя бы тем, что нет тех доп. требований нет и есть требование «семейственности».
Еще одна причина того, что я хочу начать с L3 — это чтобы посмотреть на задачу с другой стороны.
И еще есть одно обстоятельство, которое должно ускорить работу — изначальный L3 будет содержать только необходимые конструкции. Расширение только после переписывания компилятора на себе самом, а это значит, что расширения/улучшения будут более обоснованными.
Постоянная ссылка
Вот семейственность и выглядит как нечто, требующей одновременного существования языков, чтобы попробовать семейственность на деле, и скорректировать соответствующим образом проекты языков. Но если исходить из последовательной разработки языков вместе с инструментарием, столкновения можно ждать очень долго, а если не повезёт, то и слишком поздно.
Постоянная ссылка
выкинули два класса языков:
— метаязыки, такие как MPS и XText (в примитивном случае сжимаются до lex/yacc), позволяющие напрямую формулировать и синтаксис, и семантику
— Форт который похоже невозможно переплюнуть по простоте и базовости, даже ассемблер сложнее по грамматике (у Форта её по факту практически нет, парсер состоит только из примитивного лексера в десяток-два строк кода)
Постоянная ссылка
Не понял. Я вообще ничего не выкидывал. Я строю главную последовательность, вокруг неё могут существовать другие последовательности, например, что-то типа Форт.
Форт чудесный язык (то есть находится за гранью нормальности). С другого края шкалы нормальности, расположен другой чудесный язык — С++.
Опыт у меня есть и на том и на другом, впрочем, как и на многих других языках разной нормальности. Но использовать в работе чудесные языки я не хочу, это слишком трудозатратно (и скучно).
Постоянная ссылка
Я бы пошёл по пути Мульти-Оберона: по факту, база языка одна и та же. Декларация возможностей в начале объявления программы специальной директивой, которая добавляет новые функциональные возможности.
Отнесение Go ко второму уровню откровенно ошибочно — при желании можно написать ОС. Сборщик мусора можно отключить, ассемблер компилятором поддерживается.
Имхо, язык перекрывающий все 4 уровня должен начинаться с самого верхнего уровня — его можно реализовать вообще на чём угодно. Он максимально оторван от железа. С него перенос на другие платформы и должен начинаться.
Постоянная ссылка
если честно, вообще не понимаю зачем такие развесистые иерархии языков, когда принцип универсального языка программирования давно известен:
— метаязык для описания грамматики и семантики DSL-языков,
— и программирования через кодогенерацию (вывод кода в файлы)
т.е. должны быть
1) средства BNF-подобного описания грамматики (или может быть DCGб так как этот класс грамматик позволяет реализовать произвольные контекстно-зависимые языки)
2) структура данных, заточенная на работу с AST: если ядро на Python пишется, в их качестве прекрасно работают объектные графы
3) язык с операциями, заточенными на преобразования графов, и форматный вывод строковых деревьев в файлы (скрипты для сборки, исходных код на произвольных языках)
в п.3 как минимум должно выключаться полноценное сопоставление с образом (унификация), см. Elixir, Rust, Prolog
Постоянная ссылка
«язык перекрывающий все 4 уровня» — это как раз совсем НЕ ТО, что я делаю. ЯВД — это не универсальный язык, а семейство языков.
«Отнесение Go ко второму уровню откровенно ошибочно» — как я уже писал, классификация условная. Хотя Go минус GC — это совсем не Го, так как очень многое завязано именно на GC и на escape analysis.
По поводу с чего начинать разработку языка — я считаю, что со средины, то есть L2 или L3. То есть с того уровня, на котором я предпочитаю писать компилятор.
Постоянная ссылка
Запоздалый комментарий «по форме» — может, стоило уровни нумеровать не с верхнего уровня, а с нижнего, от машкодов и ассемблера? А то ведь сверху-то пределов нет А у вас там уже 0 близко
А у вас там уже 0 близко 
Постоянная ссылка
До нуля от уровня 100 еще 99 пунктов, а не хватит умножим еще на 10
Если серьезно, то за пару лет использования я привык к этой классификации. Она удобна.
Постоянная ссылка
Алексей, приходите в ЯОС, уже есть инфраструктура, вся маленькая, управляемая, кроссплатформенная, плюс-минус развитая. Обойдём C++ стороной. Сборка мусора есть, можно её ворочать куда хотите. В Обероне Вы уже как рыба в воде. Запускается на интересной плате Zybo с ПЛИС — есть простор для развития (тем более Алексей Морозов опубликовал старую версию Active Cells даже с инструкцией). Красиво, изящно, хоббийно.
Постоянная ссылка
Если «приходите» это делайте исполнение Тривиля на ЯОС, то это слишком узко. Мне надо везде А начать движение к «везде» проще с той платформы, на которой делаешь компилятор.
А начать движение к «везде» проще с той платформы, на которой делаешь компилятор.
Постоянная ссылка
Спасибо, понял.
Постоянная ссылка
На всякий случай, ЯОС есть «почти везде», во всяком случае, на Linux и Windows. Я просто был уверен, что Вы это знаете, поэтому понял ответ как вежливую форму отказа, при том, что реальные причины другие. Но теперь подумал, вдруг забыли или что-то.
Постоянная ссылка
ЯОС может исполняться под другими ОС примерно как wine или wsl, имея доступ к хозяйской файловой системе, сети и окошку в оконном менеджере. Т.е. это не только ОС, но и платформа для разработки приложений. Не исключено, что придётся заняться и запуском на Андроид в будущем году.
Постоянная ссылка
Спасибо. Я не знал, буду иметь ввиду.
Постоянная ссылка
А насколько везде? Полный список есть?
Постоянная ссылка
Вашу классификацию я бы слегка модернизировал, т.к. мир развивается, акценты смещаются.
У1: приложения
У2: приложения и высокоуровневые библиотеки;
У3: приложения, критические по производительности или безопасности, и библиотеки;
У4: ОС, драйверы, низкоуровневые библиотеки.
У3 делится на два, т.к. критический по производительности (майнинг, техническое зрение, цифровая обработка звука) — это не то же, что критические по безопасности (эмуляторы, ядра ОС). Там будут разные (противоречивые) требования.
У4 тоже делится на два, т.к. есть взаимодействие с железом, это одна часть ОС. А вот низкоуровневые библиотеки и ядро ОС уже надо относить в той или иной части У3, в зависимости от задачи. Если пишем ОС общего назначения, живущую во враждебном мире, то к безопасной части У3. Если ОС спец.назначения (многодорожечный магнитофон или для майнинга), то к опасной части У3. То же и касается низкоуровневых библиотек. Если это библиотека шифрования или сетевой стек, то для неё безопасность важнее производительности.
Понятно, что реально никто пока не готов признать, что в ОС общего назначения безопасность важнее производительности, однако это всё равно придётся сделать, лучше сработать на упреждение.
Таким образом, уровней может остаться 4, но с чуть другой нарезкой. Или может быть дальше что-то можно сократить. У меня были подобные мысли, но думаю, что хватит 3 уровней.
* ассемблер (от него всё равно никуда не деться, это очевидно из чтения исходников A2)
* язык типа активного оберона, точнее, семейство с акцентами в безопасность или скорость.
* может быть третий вровень, «интер-активный оберон», или «лисп», но я пока в сомнениях — может быть, без него можно обойтись.
Постоянная ссылка
Разделение на уровни условное, я тоже 4 года назад думал, что достаточно 3-х уровней, потом коллега Сергей Салищев из СПбГУ предложил 4-х уровневую классификацию. И мы её теперь используем.
Я думаю, что жизнь покажет. Возможно, будет не 4 языка, а меньше, так что какой-то из уровней будет накрыт не отдельным языком, а диалектом другого языка. Впрочем, возможно, что языков будет больше. Щупать надо…
Постоянная ссылка
Поскольку ЯОС перекомпилируется 2 минуты, то это органично вкладывается в концепцию выходного дня. А так пока дождётесь компиляции — уже и выходной закончится. И ещё вопрос — нет ли тут конфликта интересов, Вы же вроде уже занимаетесь разработкой ЯП на работе?
Постоянная ссылка
На уровне Тривиля никакого конфликта интересов не может быть, я использую очевидные вещи и свои же наработки по компонентному ассемблеру.
Постоянная ссылка
Еще раз перечитал статью. Интенсивное программирование — класснай цель, но как именно мы можем радикально повысить эффективность использования ресурса программистов?
Я бы сказал, что в статье выдвигается гипотеза — через повторное использование компонентов. Честно говоря, у меня есть сомнения, и вот какие. У нас уже есть хорошие хранилища компонентов, которые не кросс-языковые, иногда не бинарные, а в исходриках (npm), но все же есть. Однако в рамках одного ЯП что-то не похоже, чтобы это помогало перейти к интенсивному программированию, не так ли? По всей видимости есть масса барьеров к еще более широкому повторному использованию, но они не названы, и не сказано, как они будут сниматься. Назову парочку:
1. Оформить компонент описанием и качественно вести версии — крайне дорого
2. Знать какие компоненты есть в хранилище — тем сложнее, чем их больше
Еще можно сказать, что вообще-то в отрасли довольно много всего доступно для повторного использования — библиотеки и фреймворки на техническом уровне, бизнес-платформы на прикладном уровне. Что нам может служить подтверждением того, что глубину повторного использовария действительно можно увеличить еще?
Постоянная ссылка
«У нас уже есть хорошие хранилища компонентов, которые не кросс-языковые, иногда не бинарные, а в исходриках (npm), но все же есть.»
То есть другими словами у нас нет хранилищ кросс-языковых, бинарных компонент, поэтому мы, как минимум, для каждого языка и еще чаще изобретаем велосипеды и тратим в десятки (сотни) раз больше сил/ресурсов, чем могли бы.
А что было бы если мы хотя бы малую часть от освободившихся ресурсов тратили на оформление компонент и их организацию?
Постоянная ссылка
На чем строится оценка в 10-100 раз?
Постоянная ссылка
Я уже много писал об этом в разных местах и повторяться мне не хочется. Вот здесь «История разработки среды «Вир» и результаты» в Технология разработки мультиплатформенных программ можно посмотреть на цифры того, к чему приводит последовательное программирование на компонентах.
Опыт Вира: Хорошие компоненты действительно сложно сделать, и вначале программирование на компонентах идет медленнее, да еще и думать приходится гораздо больше. И много раз переделывать компоненты. Но после того, как начальный этап пройден, разработка ускоряется. Во сколько раз — трудно сказать, непонятно как мерять. У меня не было возможности делать одну и ту же программу на компонентах и вручную. Если мерять в трудозатратах, включая весь жизненный цикл программы, то 100 раз для больших программ представляется скорее преуменьшением.
Постоянная ссылка
Писали много раз, но каждый раз непонятно, откуда оценка затрат труда. Модели с формулами есть? Хотя бы как в уравнении Дрейка с неизвестными коэффициентами.
Постоянная ссылка
Без проблем, и формула и график:
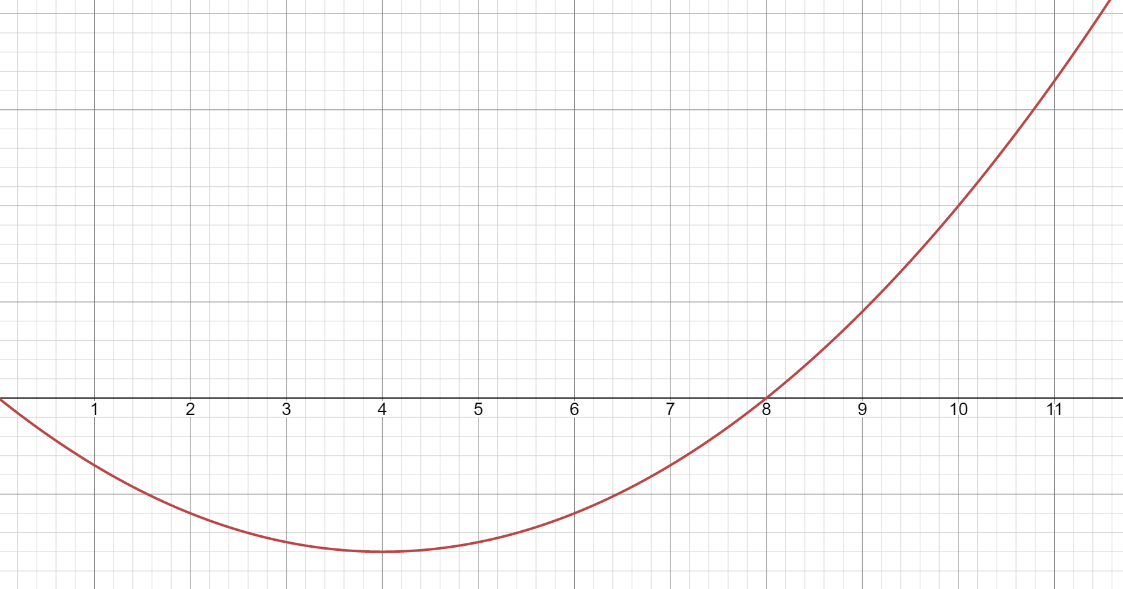
Формула: y = (x-4)**2 * 0.1 -1.6
А если серьезно, то зачем на это тратить время? Я на своем опыте убедился. А какое будет ускорение, в общем, не важно. Будет производительность выше хотя бы на 30%, уже замечательно.
Постоянная ссылка
Затем, что это часть инженерного подхода. Так-то может быть и не на 30% больше, а наоборот.
Постоянная ссылка
Хорошее замечание.
Можно добавить один слоновий пункт с позиции программиста:
3. Компоненты сложно переиспользовать, а легко переиспользуемые компоненты сложно создавать.
Легче всего переиспользовать умеренное число хорошо подогнанных друг к другу довольно мелких компонентов, созданных по определённым правилам. Система таких компонентов является языком и его стандартной библиотекой. А связывание таких компонентов является программированием.
Постоянная ссылка
А притом не так много найдёте сред, полностью свободных от Си и Си++. Эти языки начали резко выходить из моды. Сейчас это заметно только тем, кто внимательно за этим смотрит, но есть звоночки в Андроиде, в Линуксе и даже АНБ рекомендовало не пользоваться этими ЯП. Так вот, ЯОС уникальна тем, что в режиме ОС она полностью свободна от Си тулчейна, а в режиме приложения — в максимально возможной степени. Даже своя кросс-компиляция, т.е. для переноса на новые платформы не нужен компилятор Си (другое дело, что и перенести особо некуда из-за неразвитости). При том, как я думаю, инфраструктура go всё же зависима от Си и Си++. С учётом этого, ЯОС исключительно перспективна, жаль, что это вижу только я
Постоянная ссылка
Криво фразу составил. Звоночки разные:
* в Linux Торвальдс допустил Rust в качестве системного ЯП для ядра
* в Андроид идёт активное внедрение Rust, вот более чем годовалая статья: https://xakep.ru/2021/04/09/rust-android/
* АНБ рекомендовала отказаться от Си и Си++
Однако Раст торгует безопасность за усложнение разработки, а Обероны торгуют безопасность за производительность программ. Разные компромиссы — разные результаты. Самое время выйти на это игровое поле с Оберонами. Строя язык на основе С++, Вы садитесь в корабль, который начинает тонуть. Кроме того, сам-то Раст тоже основан на C++, т.к. его единственный известный мне компилятор написан на LLVM.
В этом смысле ЯОС изначально свободна от тех грехов, от которых Раст является лишь частичной индульгенцией.
Возможно, я неправ и есть варианты голанга, полностью свободные от Си/++. В принципе тогда это примерно эквивалент Оберона, не считая того, что ЯОС уже есть, а подобных по мощи проектов на голанге я пока не видел.
Постоянная ссылка
Может еще один звоночек, а может и нет: https://github.com/carbon-language/carbon-lang
Вот это на мой взгляд, совсем не довод. Мало ли на чем написан компилятор. Вот то, на чем написан run time, действительно, имеет значение, так как вносит семантику того языка.
Как язык, Go гораздо выразительней Оберона. Сегодня говорил об этом немного на семинаре памяти Поттосина, отвечая на вопрос, почему Модула-2 и Оберон не выдержали конкуренции.
Первый, шутливый ответ был — «народ не тот». Серьезный же ответ: слабые библиотеки и недостаточный полиморфизм в языке.
Постоянная ссылка
Есть понятие доверенного компилятора, и в этом случае это довод. Без ограничения сложности компилятора и написания компилятора на безопасном языке нельзя гарантировать его безопасность. Разница в выразительности между Go и Обероном некритична, кроме того в ЯОС я допиливаю язык, в т.ч. в направлении приближения к Go. Хотя с Go тоже далеко не всё радужно, я бы не назвал его хорошим безопасным языком. Он всего лишь «лучше C++»
Постоянная ссылка
1) В моем понимании, для того, чтобы язык был безопасным должны быть выполнены (как минимум) два требования:
— null safety
— и доказанная корректность типовой системы
Что означает, что Оберон и Го не являются безопасными. Из языков, которые наверху рейтингов, претендуют на «звание» безопасный: Rust, Swift и Kotlin. Впрочем, второе требование ни для одного из них не выполнено. Более того, для Kotlin есть доказанная «дырка» (в работе Александра Когтенкова). Понятно, что дырку заделают со временем, но сейчас это так.
2) Я не буду спорить про то, на каком языке писать ОС. Последний раз я участвовал в разработке ОС лет 35 тому назад, и не считаю себя специалистом в этой области. Я мог бы сослаться на провал Microsoft Singularity, но проект провалился, скорее всего, не только из-за языка, а может быть, и вообще не из-за языка.
Но вот то, что касается языка для разработки компиляторов, то, как человек, который писал компиляторы и на Обероне и на Го, скажу, Го гораздо лучше. И это благодаря полиморфизму, богатому набору типов и хорошим библиотекам. Го не идеальный ЯП, и я даже не могу назвать его хорошим ЯП. Я знаю в нем не менее 7 «дырок» плюс странные решения в дизайне. Знаю практически, так как наступал на эти грабли. И я уверен, что с добавлением generic types/functions, граблей стало больше.
Постоянная ссылка
Первая проблема, которая не решена в современном ИТ — это безопасность памяти (обращение к уже несуществующим объектам, неверная интерпретация типа данных, выход за границы массива). АНБ говорит, что 70% уязвимостей вызваны именно ей. И Го, и Оберон, и Ява закрывают эту дыру, казалось бы. Однако, если внутри рантайма где-то есть Си, то дыра остаётся, притом она остаётся в той глубине, куда программист обычно не лазает. В Обероне всё написано на Обероне и там есть тоже unsafe, но в него слазить легко. Слабое утешение, однако и в Rust тоже есть unsafe. Null safety можно добавить. ЯОС написана на своём языке, Яр-22, это не Оберон, язык подлежит изменениям. Но мне не кажется это критичным. Программа в худшем случае упадёт где не надо, но отсутствие null safety не создаёт ситуации, когда можно выполнить произвольный код. Что касается доказанной безопасности системы типов, то это лишь одна часть работы по доказыванию корректности, неясно, зачем именно её так выделять. Про полиморфизм в го не понял, потом спрошу.
Постоянная ссылка
Можете уточнить, что Вы имеете ввиду под провалом OS Singularity? Завершение проекта или невыполнение каких-либо поставленных исследовательских целей?
Постоянная ссылка
Я не отслеживаю работы по ОС, так что подхожу формально — проект закрылся, ОС не появилась. Значит — провал.
Постоянная ссылка
Алексей, тему полиморфизма можно дальше обсуждать. Например, аналог interface{} в Активном Обероне уже есть, хотя работает только для записей, но есть желание и планы расширить его возможности. Просто интерфейсы в го вызывают у меня сомнения (их утиность), но и такое можно сделать. Но по опыту могу судить, что если человек что-то решил в своём хобби-проекте, то его уже не свернуть с выбранного пути. Это так в нашем случае? Просто чтобы я зря не тратил время.
Постоянная ссылка
Ответил здесь: http://алексейнедоря.рф/?p=469