
Отвечаю на комментарий Игоря отдельной записью, чтобы не ужиматься.
Мозги мои пока скрипят, разворачиваясь от языкотворчества и технологических вопросов к компонентам, поэтому комментарий Игоря для меня очень важен. Спасибо!
Теперь по пунктам
1. Разве несколько уже соединенных компонент — это не компонент?
Да, компонента (я предпочитаю женский род, см. например, http://new.gramota.ru/spravka/trudnosti?layout=item&id=36_175)
2. Я же могу соединить А1+А2+А3 в A, B1+B2+B3 в B, и затем соединить A+B? Вспоминаем также давний разговор про А-компоненты (которые собираются) и D-компоненты (которые пишутся более традиционным способом)
Конечно.
3. А тогда что такое Схема, если это не A-компонент? Имхо, это понятие становится лишним
А что такое А-компонента, если это не Схема? Но это шутка, на мой взгляд, это разные вещи, давайте подумаем на эту тему.
Рассмотрим схему:
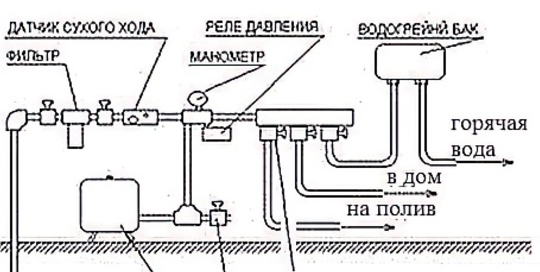
То, что это схема какого-то водоснабжения, нам не важно. Это точно схема, и это схема абстрактной компоненты. Почему абстрактной? А потому что её составные части не конкретизированы: какое-то реле, какой-то фильтр, и т.д. Понятно, что сами эти слова «реле», «фильтр» уже задают требования к компоненте, но это слишком общие требования, которые должны быть конкретизированы — например, размером трубы, требованием к пропускной способности и т.д.
Если все необходимы конкретизации заданы (например, инвентарным номером производителя фильтра) то можно приступать к сборке. Тогда мы получили схему конкретной компоненты, готовой для инстанциации (установки). Если мы говорим о программной компоненте, то конкретизация её — это, как минимум, для каждой компоненты:
- указание адреса, где взять «код» компоненты,
- или указание адреса «фабрики» (factory), например, в виде URL, по которому можно отправить запрос и получить экземпляр компоненты.
Вот здесь уже видно, что мне не хватает терминологии. Что такое код компоненты? Что такое экземпляр компоненты?
Экземпляр компоненты — это структура в оперативной памяти (по аналогии с экземпляром класса) или нет?
Компонента — это совокупность всего, что нужно, чтобы сделать экземпляр компоненты на конкретном устройстве или нет? То есть это аналог «типа класса» или нет?
Схема — это только описание (чертеж, blueprint), или это описание + код + ресурсы + документация?
Надеюсь, мне удалось показать, что есть вопросы и надо определяться с ответами. Может быть, эти ответы у меня были, но сейчас пришло время подумать заново. Я не буду сходу пытаться вспомнить ответы или придумать ответы, для этого нужно время.
4. Когда кто-то создает экземпляр А-компонента, должен ли он знать его устройство, или сам А-компонент как Схема знает свое устройство, но только на один уровень вглубь, до компонентов, из которых состоит, которые как-то соединены между собой и еще подключены к зависимостям?
Это замечательный вопрос про белые, серые и черные ящики и про зависимости. Но отвечать на него надо уже договорившись о терминологии.
5. Не является ли программа на верхнем уровне просто А-компонентом, который подключен к зависимостям типа INetIO, IFileIO и IConsoleIO, IWindowsGUI, etc?
На первую часть (игнорируя названия зависимостей), я могу ответить: Да. То, что я сейчас понимаю, говоря «программа» — это компонента. И она может соединятся с другими компонентами, образуя программную систему боле высокого уровня.
Ну и засим предлагаю посмотреть на результаты моих экспериментов с компонентным подходом с DSL на макросах Rust:
Компонент-консольное приложение:
https://github.com/iamhere2/HLCD-Researches/blob/master/ChessApp/src/RustMacros/src/chess_app.rs
Один из компонентов следующего уровня:
https://github.com/iamhere2/HLCD-Researches/blob/master/ChessApp/src/RustMacros/src/chess_app/console_ui.rs
Это работающий код, если что. Конечно, приложение недоделанное, но принцип показан и это работает.
Да, на мой взгляд — это компоненты, и вполне лаконично описанные.
Единственно, что я сразу хочу поставить себе как задачу — описание компонент (видите, появился еще один неопределенный термин) должно быть на отдельном языке (отделенном от языка программирования, точнее, нейтральном по отношению к языкам программирования).
Постоянная ссылка
А что означает эта нейтральность? В описание компонент будет входить типы данных, посредством которых компоненты должны взаимодействовать?
Постоянная ссылка
Да, интерфейс (протокол) взаимодействия должен фиксировать типы данных. Современные языки программирования фиксируют примитивные данные (int32, int64, …) чтобы кросс-платформенность была естественной. В составных данных (массивах, записях) тоже надо наводить порядок. Например, вводить ограничения на передаваемые данные. Тут можно посмотреть на Swift, который определяет понятие Sendable types.
Постоянная ссылка
На типах данных языковая нейтральность заканчивается, если я её правильно понимаю. Либо типы соответствуют языку, позволяя ему бесшовно взаимодействовать с компонентами, либо компоненты вводят ещё один язык, одинаково неудобный для нижних языков(такая вот нейтральность), но тогда всё равно остаётся возможность создать такой нижний язык, для которого типы от компонентности максимально соответствуют его собственным типам и нейтральность снова заканчивается. Поэтому, всё-таки, что означает эта нейтральность?
Постоянная ссылка
Я же все время говорю о «Семействе языков», которые основаны на обобщенной системе типов и общей поддержки исполнения, например, в статье «Интенсивное программирование».
Конечно, всегда можно взять, например, Форт, JavaScript и Rust и получится, как в известной басне (кто из них Лебедь?). Не надо пытаться проверять, может ли японская бензопила перепилить лом — и так ясно, что не может.
А в рамках семейства языков нейтральность есть by design.
Постоянная ссылка
То есть, нейтральность, в данном случае означает заточенность под соответствующие языки? По этим языкам тоже есть вопросы по адресуемости. Подразумевается, что компоненты смогут обмениваться указателями или они будут изолированы по памяти?
Постоянная ссылка
Предполагаю, что изолированные будут изолированы, см. например, dart isolates, а не изолированные (по памяти) смогут работать с общей памятью.
Скорее всего, нужно будет сделать градацию компонент или интерфейса компонент по степени изолированности.
Пока никакой конкретики, так как мы в начале исследования…
Постоянная ссылка
Те, что не изолированы, как будут обмениваться указателями с разными типами распределителями памяти (сборщик мусора, подсчёт ссылок, явное освобождение), указатели между которыми, как минимум, не вполне совместимы.
Изоляция по памяти — это тоже модель работы, в которой преимущество получит язык, заточенный под неё.
Постоянная ссылка
Спасибо, интересный разговор выходит, вопросы действительно есть. Попробую ответить там, где я уже много думал и пришел к какому-то выводу или просто поразмышлять на ходу.
Начнем с терминологии и семантики. Про схемы поговорим в отдельном комментарии.
1. Преамбула о виртуальной машине, возможно очевидная. Мне кажется, что важно то, что мы делаем, представлять как разработку языка описания устройства некоторой вычислительной машины (виртуальной машины), оторвавшись на время от вопроса ее реализации (компилятора и/или среды исполнения). И тогда терминологический вопрос «является ли экземпляр компоненты структурой в памяти» надо задавать/понимать исключительно в терминах _поведения_ итоговой машины. Не важно, как там что под капотом, но в итоге физическая машина с работающей программой демонстрирует такое поведение, как если бы у нас была машина, непосредственно состоящая из нескольких частей, которые мы называем [компонентами] (в этот момент — конкретными), потенциально с состоянием (памятью), соединенных так-то и так-то, и каждая из частей фрактально тоже может состоять из компонент, и компоненты нижнего уровня тоже обладают каким-то поведением. Возможно, это очевидный тезис, про виртуальную машину, но на всякий случай проговорим его.
2. Приняв этот тезис во внимание, ответим на поставленный вопрос. [Компонента] или [экземпляр компоненты] — это часть работающей (run-time) машины. При хорошей поддержке среды исполнения мы должны уметь увидеть эти конкретные компоненты так же «физично» как мы видим процессы ОС в Task manager, посмотреть состояние любой компоненты, посмотреть из каких других частей она состоит, как они связаны. Сторонники zero-cost abstractions будут против, но если мы боремся за ускорение разработки и повышение понимаемости систем, то я готов жертвовать производительностью, или это может быть специальный отключаемый режим, но зато такое видение _возможной_ поддержки в run-time помогает нам видеть цель и не путаться. А в design-time у нас есть [описание] = [определение] (definition) компоненты = [тип компоненты] в каком-то [модуле].
3. [Модули] (design-time) проограмм (исходные или бинарные) содержат [определения]/инструкции (definition) как создавать [компоненты] (как они устроены) в run-time. Ну и другие определения, например, для типов данных и интерфейсов. Это все — инструкции как построить нашу машину из кубиков (А-компоненты) и как построить сами кубики (Д-компоненты). Тут получается различение вполне по классике SEI модулей и компонент и это более-менее выровнено с системноинженерными понятиями с точностью до специфики софта вообще. Про то, что компоненты могут [состоять] из компонент мы сказали, про то, что компоненты [реализуют] определения из модулей мы сказали, а вот отношения между модулями надо обсуждать отдельно. Кажется, там есть место и [зависимостям] по импорту определений, и отношению вложенности тоже, как в Rust, это видится полезным. Тогда модули могут и [требовать] другие модули (для использования тамошних определений), и [состоять] из других модулей (что может определять кванты компиляции, видимость, и т.п.).
4. Стараемся не тащить без нужды ничего из ООП, чтобы ненароком не заразиться какой-то неудачной терминологической пакостью. Поэтому никаких «классов» и «объектов». ИМХО, испорченные напрочь термины и мне их совсем не жалко.
Постоянная ссылка
Читаю и соглашаюсь… Не вызывает желания спорить, и это радует.
Про виртуальную машину я писал в Всеплатформенная разработка или Если б я был султан
О терминологии: в ходе работы над Виром и Вир-2, у меня более-менее устоялась терминология, относящаяся к времени исполнения, а именно что программа состоит из Рабочих столов, на Рабочем столе стоят Верстаки, к Верстаку подключены Инструменты. Каждый Рабочий стол, каждый Верстак и каждый Инструмент — это компонента (во время разработки), но во время исполнения компонента специализируется и превращается в инструмент.
Мне кажется, что разделение терминологии на терминологию время разработки и терминологию времени исполнения (design time/execution time) это очень полезное действие, которое ведет к ясности, а следовательно к сокращению времени разработки.
Берем обобщенную компоненту сортировки (design time), вставляем её в программу и она превращается в конкретный инструмент сортировки, например, мух и котлет.
Точно так же, подключенный текстовый редактор — это инструмент, независимо от того, является ли он одной Д-компонентой или сложно-составной А-компонентой.
Постоянная ссылка
Про несколько языков. Думал.
Действительно, А-компоненты получаются описаны на несколько другом языке (подъязыке) нежели чем Д-компоненты. Вообще, «подъязыков» можно выделить довольно много:
— для описания алгоритмов (~тел методов/функций)
— для описания интерфейсов «одиночных вызовов» (~прототипов функций в C)
— для описания структур данных
— для описания собственно данных (литералы, массивы, мапы, всякие JSON/XML, etc)
— для описания структуры Д-компонент (~классов в ООП)
— для описания структуры А-компонент (нет аналогий в ООП/ФП)
— для описания интерфейсов компонент (~интерфейсов в ООП)
— для описания модулей, зависимостей (импортов), правил видимости определений (definition) из модулей (всякие export/import/pub(super)/unit {name})
— для описания правил сборки и загрузки модулей из файловой системы/репозиториев (~package.json, cargo.toml, etc)
Многие из этих языков так тесно связаны друг с другом, что и не разорвать. Например, понятно, что в описании алгоритма нам может быть нужно инициализировать некоторую локальную структуру данных (даже если мы определили эту не по месту, что «удобнее», а заимпортировали из модуля, определяющего эту структуру на другом языке).
Но большинство этих языков исторически связаны (спаяны? сплавлены?) скорее удобством и традицией. «Чтобы быстрее писать код не приходя в сознание». Например, то, что мы привыкли в одном файлике (вроде как одним парсером разбираемом) определять и структуры классов, и зависимости модулей, и алгоритмы, и много чего еще. Можно попробовать сперва описать эти языки максимально раздельно, чтобы разобраться. Как эксперимент. А потом может предложить как это компактно слить воедино для удобства/скорости машинописи.
Постоянная ссылка
И наконец, про схемы. Прекрасный пример, спасибо. Действительно, поднимает вопрос насчет обобщений.
Хочу обратить внимание на несколько моментов:
1. Банальное. Эта схема обозрима, т.к. проста. Элементов не много. К этому надо стремиться.
2. Эта схема одноуровневая. Это уже важно. Мы не видим деталей манометра и датчика, например, хотя понятно, что они есть. Называете ли вы [схемой] только такие одноуровневые штуки или может все дерево компонент как в Вире?
3. Действительно, без уточнений какую _точно_ взять [реализацию/версию] дочерних компонент (хеш? адрес модуля с версией?), построить (в runtime) данный компонент «Домашнее ХВС/ГВС» невозможно. Тогда почему такое определение/описание нужного нам целевого компонента вообще будет полезно? Ну, как предварительный дизайн для людей и LLM — допустим, но это неинтересно, хочется поговорить сразу о строго-машино-читаемых вариантах использования.
Итак, вариант использования A для такой схемы — построение в runtime. Тут нужны или точные спецификации реализаций, или, действительно, может быть отдельный Поставщик (~IoC container) который откуда-то знает эти спецификации и может их выдать по некоторому абстрактному указанию, «уконкретить». Возможно, тут действительно есть место Поставщику, отдельному от Схемы, а не как мне казалось ранее.
Конечно, в частном случае, сам А-компонент может выступать Поставщиком, если его опредление содержит ссылки на точные определения дочерних компонент. В моем прототипе так и было сделано (компонент импортирует дочерний модуль и ссылается на тип компонента из него). Я не видел необходимости разделения Схемы и Поставщика, но это было бы интересно обсудить/обдумать/отпрототипировать. Какая польза от такого разделения? Какие кейсы в практике?
Вариант использования Б — на самом деле, можно верифицировать/скомпилировать /перевести в бинарный модуль компонента «Домашнее ХВС/ГВС», даже не имея Поставщика, который скажет конкретные спецификации реализаций, если у нас есть точные (хеш? адрес модуля с версией?) спецификации интерфейсов (отдельный разговор про duck typing). Это просто полиморфизм по интерфейсам, как в SOLID. Но действительно в runtime кто-то как-то кому-то должен предоставить живые ссылки (нужен другой термин — коннекторы? порты? оконечные точки? соединители? коннекторы — англицизм, но удобный) на какие-то компоненты, реализующие нужные интерфейсы (можно сказать, что [интерфейс] — это [тип коннектора]).
Тут еще возникает интереснейший вопрос про возможное разделение [времени сборки/инициализации] компонента и [времени его работы]. А еще бывают не самые плохие дизайны с циклическими связями дочерних компонент в runtime, и хорошо бы это уметь делать.
Опять выходит, что, действительно, роли можно поделить сильнее, чем сделал я в своем прототипе — [Схема] (вполне себе просто определение компонента, т.е. тип компонента) как то, что определяет его целевую рабочую структуру, и Сборщик как инфраструктурный элемент, которй по схеме в runtime соединит дочерние компоненты вместе. В моем прототипе по DSL-определению (схеме) Сборщик генерировался автоматом и без каких-либо настроек, как функция-конструктор Компоненты в ее модуле. Потенциально это может быть как-то сильнее параметризовано, алгоритм сборки может быть не единообразным.
Итого, при максимальном разделении функций, которое сейчас мне видится:
— [определение Д-компоненты] = [«Схема»], на своем языке, потенциально с неуказанными реализациями, но с точно (+/- duck typing или traits) указанными интерфейсами, иначе не видно смысла (предложите?)
— «Поставщик» который на основе каких-то подсказок из схемы или имен интерфейсов или чего-то еще может указать на точное определение (тип) дочернего компонента. Потенциально — свой язык типа паттерн-матчинга. И нужен кейс для примера, когда это нужно отделять. Вообще говоря, Поставщик может выполнять свою работу в design time (ранее связывание), а может и в runtime (позднее связывание).
— «Сборщик» который на основе Схемы с помощью Поставщика получает указания на определения дочерних компонент, создает их (рекурсивно? или делегируя соответствующему другому Сборщику?), и затем соединяет коннекторами по схеме. Возможно, подключает также внешние интерфейсы, как того требует Схема. В нашем примере — «труба 3/4 дюйма для подачи холодной воды». Очевидно, что нужен стандартный сборщик, но может быть иногда нужен и совершенно специальный, на каком-то языке, возможно, языке алгоритмов, потому что вроде похоже на простую императивную последовательность. Не предоставив коннекторы к внешним интерфейсам нашего А-компонента, сборщик нельзя вызвать, ведь он должен выдать готовый к работе компонент.
Кстати, еще у меня была такая интеересная идея: иногда какой-то интерфейс можно реализовать просто набором функций какого-то модуля, если конкретная реализация stateless. В моем примере это был интерфейс Игрока, реализованный в частном случае простыми pure functions. Указать на это («интерфейс реализован pure функциями в модуле X») было бы ролью Поставщика, а предоставить автоматически адаптер от полиморфного коннектора к статическим функциям из указанного модуля было бы работой Сборщика.
Разделили, это хорошо. Но хорошо бы понять, а какие кейсы для такого разделения и не нужно ли сразу соединить обратно Может ли быть полезно определение А-компоненты (схемы) без определения точного и полного алгоритма Сборщика для этого компонента? Нужен кейс, когда это полезно, а иначе это все сразу стоит схлопнуть обратно и сказать что Сборщик всегда или стандартный или вшивается в сам компонент рядом со Схемой.
Может ли быть полезно определение А-компоненты (схемы) без определения точного и полного алгоритма Сборщика для этого компонента? Нужен кейс, когда это полезно, а иначе это все сразу стоит схлопнуть обратно и сказать что Сборщик всегда или стандартный или вшивается в сам компонент рядом со Схемой.